How to Set Up a Data Pipeline in Azure Data Factory for Importing Data from Azure Blob Storage to Databricks delta lake
- Posted in:
- Databricks

Data pipelines are essential for modern data solutions, and Azure Data Factory (ADF) provides a robust platform for building them. In this blog, we’ll walk through the process of setting up a pipeline in Azure Data Factory to import data from Azure Blob Storage into Databricks for processing.
Step 1: Prerequisites
Before setting up the pipeline, ensure the following prerequisites are met:
- Azure Blob Storage: Your source data should be stored in an Azure Blob Storage container.
- Azure Databricks Workspace: A Databricks workspace and cluster should be set up for data processing.
- Azure Data Factory Instance: Have an ADF instance provisioned in your Azure subscription.
- Linked Services Configuration:
- Azure Blob Storage Linked Service: This enables ADF to connect to your data source.
- Azure Databricks Linked Service: This enables ADF to connect to the target Databricks Delta Lake.
Both linked services are critical for establishing connections and configuring data pipelines between Blob Storage and Databricks.

- Access Permissions:
- ADF needs Contributor access to Blob Storage and Databricks.
- Ensure you have access to generate a Databricks personal access token.
You will also need to configure the Blob Storage access token in Databricks. This ensures the underlying Spark cluster can connect to the source data seamlessly. Without proper configuration, you may encounter errors like the one shown below.
ErrorCode=AzureDatabricksCommandError,Hit an error when running the command in Azure Databricks. Error details: <span class='ansi-red-fg'>Py4JJavaError</span>: An error occurred while calling o421.load.
: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Container salesdata in account cxitxstorage.blob.core.windows.net not found, and we can't create it using anoynomous credentials, and no credentials found for them in the configuration.
Caused by: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Container salesdata in account cxitxstorage.blob.core.windows.net not found, and we can't create it using anoynomous credentials, and no credentials found for them in the configuration.
Caused by: shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Container salesdata in account cxitxstorage.blob.core.windows.net not found, and we can't create it using anoynomous credentials, and no credentials found for them in the configuration..

{kind=link}
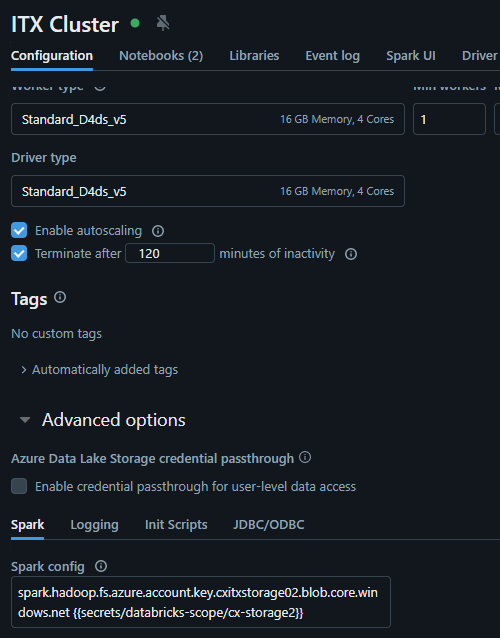
In the Cluster Configuration you will need the following:
spark.hadoop.fs.azure.account.key.<account_name>.blob.core.windows.net {{secrets/<secret-scope-name>/<secret-name>}}
You can use Databricks CLI to create scope and secret with the below commands
- databricks secrets create-scope <scope name>
- databricks secrets put-secret --json '{ "scope": "<scope name>",
"key": "<secret-name>",
"string_value": "<storage account key value>",
}
Step 2: Create an ADF Pipeline
Add a Copy Data Activity:
- Add the Copy Data activity into the pipeline.
- Set the Source to use the Blob Storage dataset and the Sink to use the Databricks Delta Lake dataset.
Add Data Transformation (Optional):
- Use a Databricks Notebook activity to run transformation scripts.
- Link the notebook to your Databricks cluster and specify the notebook path.
Step 3: Test and Schedule the Pipeline
Test the Pipeline:
- Use the Debug feature in ADF to run the pipeline and verify its functionality.
Schedule the Pipeline:
- Add a time-based or event-based trigger to automate pipeline runs.
